Semi-supervised Learning via Transductive Inference
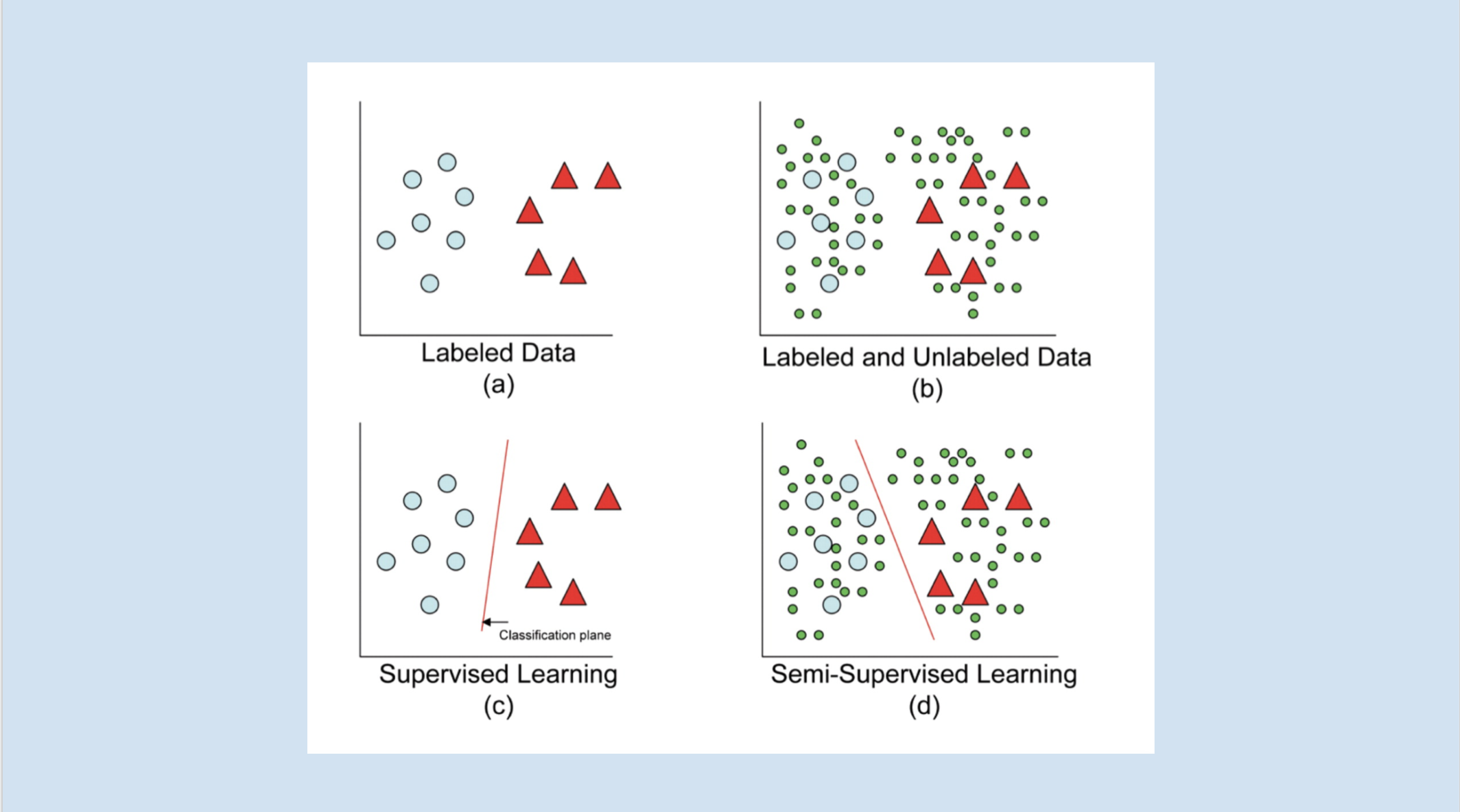
In many real-life applications, the labeling of training examples for learning is costly and sometimes even not realistic. That may leads to a situation when huge amount of observations are available while just few of them are labeled. In this case, learning on labeled examples only may result in an inefficient supervised model. In semi-supervised learning, it is generally expected that unlabeled examples contain valuable information about the prediction problem, thus their exploitation leads to an increase of prediction performance.
In this tutorial, we are going to discuss a contribution of transductive inference in the study of semi-supervised learning. Namely, a transductive bound over the risk of the multi-class majority vote classifier will be introduced to you. This result is used to find dynamically thresholds in the self-learning algorithm. The algorithm iteratively assigns pseudo-labels to a subset of unlabeled training examples that have their associated class margin above a threshold obtained from the transductive bound.
Download Slides
Back to Past Events